Java Web 从入门到退坑 —— 第十章 文件的上传和下载
By -gregPerlinLi-
文件的上传和下载,是非常常见的功能,很多的系统或者软件中经常会使用到文件的上传和下载,比如:QQ 头像,就是用了上传,邮箱中也有附件的上传和下载功能,OA 系统中审批的附件材料的上传
1. 文件的上传介绍(重点)
1. 要有一个 from 标签,method=post 请求
2. from 标签的 enctype 属性值必须为 multipart/from-data 值
3. 在 from 标签中使用 input type=file 添加上传的文件
4. 编写服务器代码(Servlet)接受,处理上传的数据
multipart/from-data 表示提交的数据以多段(每一个表单项一个数据段)的形式进行拼接,然后以二进制流的形式发送给服务器
1.1. 文件上传时发送的 HTTP 协议内容
请求头:
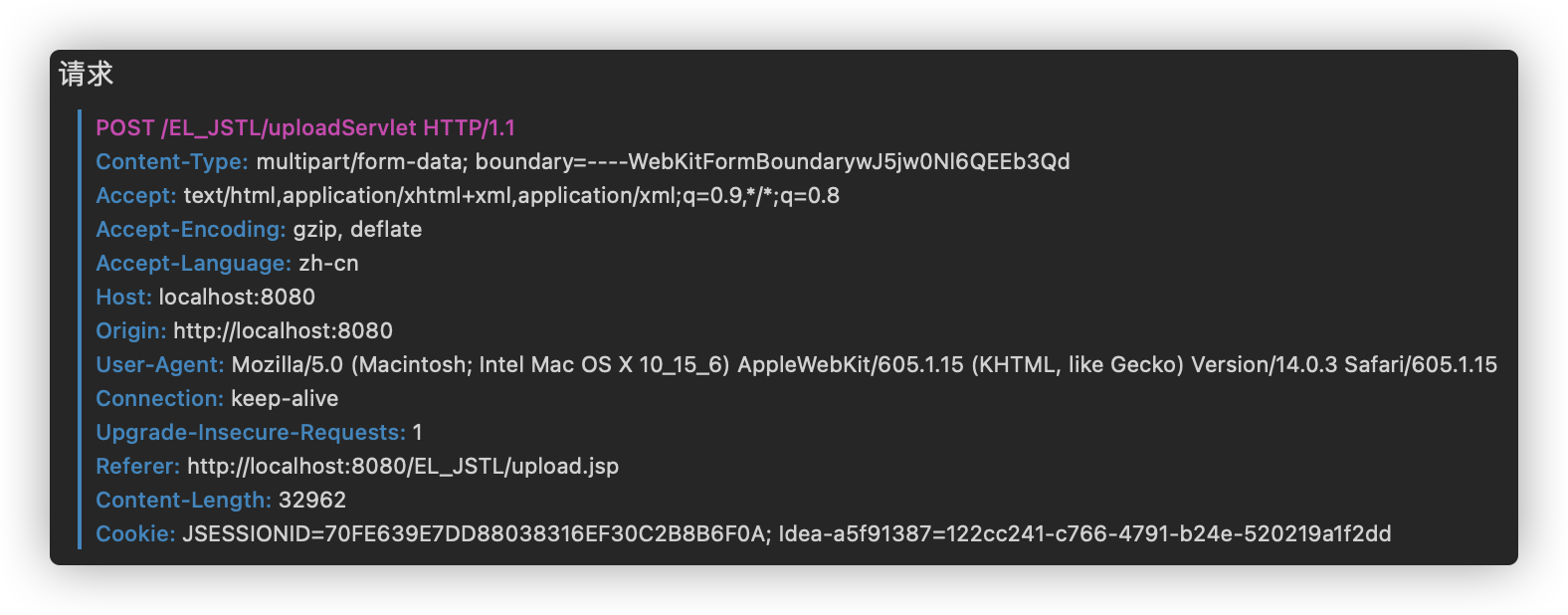
Content-Type 表示提交的数据类型
multipart/from-data 表示提交的数据以多段(每一个表单项一个数据段)的形式进行拼接,然后以二进制流的形式发送给服务器
boundary 表示每段数据的分隔符(由浏览器随机生成),它是每段数据的分界符
请求体:
------WebKitFormBoundarywJ5jw0Nl6QEEb3Qd
Content-Disposition: form-data; name="username"
gregPerlinLi
------WebKitFormBoundarywJ5jw0Nl6QEEb3Qd
Content-Disposition: form-data; name="photo"; filename="Snipaste_2020-11-17_16-01-12.jpg"
Content-Type: image/jpeg
------WebKitFormBoundarywJ5jw0Nl6QEEb3Qd--
请求体中的第1、5行表示一段数据的开始,空行后面表示的是表单项的值(由于浏览器的原因,上传的文件不会显示出来),最后一行(多了两行 - 减号的分隔符)表示数据的结束。
1.2. commons-fileupload.jar 常用 API 介绍
commons-fileupload.jar 需要依赖 commons-io.jar 这个包,所以这两个包都需要导入。
第一步,就是需要导入这两个 jar 包。
commons-fileupload.jar 和 commons-io.jar 这两个包中常用的类:
ServletFileUpload 类,用于解析上传的数据
FileItem 表示每一个表单项
常用 API:
boolean ServletFileUpload.isMultipartContent(HttpServletRequest request);
判断当前上传的数据格式是否是多段的格式
public List<FileItem> parseRequest(HttpServletRequest req)
解析上传的数据
boolean FileItem.isFormField();
判断当前的表单项是否时普通的表单项还是上传的文件
true 表示普普通类型的表单项
false 表示上传的文件类型
String FileItem.getFieldName();
获取表单项的 name 属性值
String FileItem.getString();
获取当前表单项的值
String FileItem.getName();
获取上传的文件名
void FileName.write( file );
将上传的文件写到参数 file 所指向的磁盘位置
1.3. fileupload 类库的使用
示例代码:
注意⚠️: 要先判断上传的数据是否为多段数据(只有是多段的数据才是文件上传)
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
System.out.println("File uploaded successfully!");
// Judge whether the uploaded data is multi segment data (only multi segment data is the file uploaded)
if ( ServletFileUpload.isMultipartContent(req) ) {
// Create FileItemFactory factory implementation class
FileItemFactory fileItemFactory = new DiskFileItemFactory();
// Create a tool class ServletFileUpload class for parsing uploads
ServletFileUpload servletFileUpload = new ServletFileUpload(fileItemFactory);
try {
// Parse the uploaded data to get each form item FileItem
List<FileItem> fileItemList = servletFileUpload.parseRequest(req);
// Loop to determine whether each form item is a normal type or an uploaded file type
for ( FileItem fileItem : fileItemList ) {
if ( fileItem.isFormField() ) {
// Normal form item
System.out.println("The name property value of the form item: " + fileItem.getFieldName());
// Parameter UTF-8 to solve the problem of garbled code
System.out.println("The value property value of the form item: " + fileItem.getString("UTF-8"));
} else {
// Uploaded files
System.out.println("The name property value of the form item: " + fileItem.getFieldName());
System.out.println("The upload file name: " + fileItem.getName());
fileItem.write(new File("/.../" + fileItem.getName()));
}
}
} catch ( Exception e ) {
e.printStackTrace();
}
}
}
2. 文件的下载(重点)
2.1. 下载常用的 API 说明
response.getOutputStream();
获取响应的输出流
servletContext.getResourceAsStream();
获取要下载的资源流
servleyContext.getMimeType();
获取下载文件的类型
respose.setContextType();
通过响应头告诉客户端回传的文件类型
response.setHeader("Content-Disposition", "attachment", "filename=1.jpg");
设置响应头收到的数据将被用于下载
attachment 表示下载使用的附件
filename= 表示指定下载的文件名(可以和原文件名不一致)
示例代码:
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
// 1. Get the file name to download
String downloadFileName = "photo1.jpg";
// 2. Read the contents of the file to download (It can be read through ServletContext object)
ServletContext servletContext = getServletContext();
// Gets the type of file to download
String mimeType = servletContext.getMimeType("/file/" + downloadFileName);
System.out.println("The type if tile to download: " + mimeType);
// 3. Before the return, the response header tells the customer the type of data to return
resp.setContentType(mimeType);
// 4. Tell the client whether the received data is used for download (or response header)
// Content-Disposition: How to deal with the received data
// attachments: Indicates the attachment used for download
// filename=: Represents the file name of the specified download
resp.setHeader("Content-Disposition", "attachment;filename=" + downloadFileName);
/**
* / The slash is resolved by the server to indicate that the address is http://ip:port/projectName
* webapp directory mapped to the code
*/
InputStream resourceAsStream = servletContext.getResourceAsStream("/file/" + downloadFileName);
// Gets the output stream of the response
OutputStream outputStream = resp.getOutputStream();
// 5. Send the downloaded file back to the client
// Read all the data in the input stream and copy it to the output stream
IOUtils.copy(resourceAsStream, outputStream);
}
注意⚠️: 由于 HTTP 协议的限制,以上的方法所下载的文件名只支持 ASCII 字符,所以文件名中不能含有中文,否则将会出现乱码问题
2.2. 如何解决中文下载名乱码的问题
方案一:使用 UrlEncoder 解决 IE/Edge 和 Chrome 浏览器的中文下载名乱码的问题
如果客户端使用的是 IE/Edge 和 Chrome(基于 Chromium 架构的也可)浏览器,在设置响应头的时候可以使用 UrlEncoder() 来解决中文下载名乱码的问题
使用方法:
// 4. Tell the client whether the received data is used for download (or response header)
// Content-Disposition: How to deal with the received data
// attachments: Indicates the attachment used for download
// filename=: Represents the file name of the specified download
// URL encoding is to convert Chinese characters into xx%xx format
resp.setHeader("Content-Disposition", "attachment;filename=" + URLEncoder.encode("图片", "UTF-8"));
方案二:使用 BASE64 编解码解决火狐浏览器的中文下载名乱码的问题
如果客户端使用的是 Firefox 浏览器,那么我们需要对中文名进行 BASE64 编码操作
这时候需要把请求头: Content-Disposition: attachment; filename=ChineseName 编码成为:Content-Disposition: attachment; filename==?charset?B?xxxxx?=
=?charset?B?xxxxx?= 的含义如下
=? 表示编码内容的开始
charset 表示字符集
B 表示 BASE64 编码
xxxxx 表示文件名 BASE64 编码后的内容
?= 表示编码内容的结束
BASE64 编解码操作:
public static void base64Encoding(String[] args) throws Exception {
// Creating BASE64 codec (encoder and decoder)
final Base64.Encoder encoder = Base64.getEncoder();
final Base64.Decoder decoder = Base64.getDecoder();
final String text = "This is the content require to BASE64 encoding";
final byte[] textByte = text.getBytes("UTF-8");
// Encoding operation
final String encodedText = encoder.encodeToString(textByte);
System.out.println(encodedText);
// Decoding operation
byte[] bytes = decoder.decode(encodedText);
String decodedText = new String(bytes, "UTF-8");
System.out.println(decodedText);
}
使用方法:
// 4. Tell the client whether the received data is used for download (or response header)
// Content-Disposition: How to deal with the received data
// attachments: Indicates the attachment used for download
// filename=: Represents the file name of the specified download
Base64.Encoder encoder = Base64.getEncoder();
resp.setHeader("Content-Disposition", "attachment;filename==?UTF-8?B?" + encoder.encodeToString("图片".getBytes(StandardCharsets.UTF_8)) + "?=");
方案三:使用 ISO-8859-1 标准来解决 Safari 浏览器的中文下载名乱码的问题
如果客户端使用的是 Safari(基于 WebKit 的也可)浏览器,由于其用的是 ISO 字符编码,而且文件名需要用 UTF-8 编码,因此需要做如下改动
使用方法:
// 4. Tell the client whether the received data is used for download (or response header)
// Content-Disposition: How to deal with the received data
// attachments: Indicates the attachment used for download
// filename=: Represents the file name of the specified download
resp.setHeader("Content-Disposition", "attachment; filename="+ new String("图片".getBytes(StandardCharsets.UTF_8), StandardCharsets.ISO_8859_1));
方案四:使用 User-Agent 请求头判断,动态切换不同的方案解决所有问题
使用方法:
// 4. Tell the client whether the received data is used for download (or response header)
// Content-Disposition: How to deal with the received data
// attachments: Indicates the attachment used for download
// filename=: Represents the file name of the specified download
// URL encoding is to convert Chinese characters into xx%xx format
String agent = req.getHeader("USER-AGENT");
if ( agent.contains("AppleWebKit")) {
// If it's Safari, use ISO encoding
resp.setHeader("Content-Disposition", "attachment; filename="+ new String("图片".getBytes(StandardCharsets.UTF_8), StandardCharsets.ISO_8859_1));
} else if ( agent.contains("Firefox")) {
// If it's Firefox, use BASE64 encoding
Base64.Encoder encoder = Base64.getEncoder();
resp.setHeader("Content-Disposition", "attachment;filename==?UTF-8?B?" + encoder.encodeToString("图片".getBytes(StandardCharsets.UTF_8)) + "?=");
} else {
// If it's other browser, use URL encoding
resp.setHeader("Content-Disposition", "attachment;filename=" + URLEncoder.encode("图片", "UTF-8"));
}

