Dubbo |ˈdʌbəʊ| 分布式初体验 —— 第三章 Dubbo 高可用
1. Zookeeper 宕机与 Dubbo 直连
现象:Zookeeper 注册中心宕机,还可以消费 Dubbo 暴露的服务
原因:
健壮性:
监控中心宕机不影响使用,只丢失部分采样数据
数据库宕机后,注册中心仍能够通过缓存提供服务列表查询,但不能注册新的服务
注册中心对等集群,任意一台宕机后,将自动切换到另一台
注册中心全部宕机后,服务提供者和服务消费者仍能够通过本地缓存通讯
服务提供者无状态,任意一台宕机后,不影响使用
服务提供者全部宕机后,服务消费者应用将无法使用,并无限次重连等待服务提供者恢复
高可用: 通过设计,减少系统不能提供服务的时间
2. 集群下的 Dubbo 负载均衡配置
在集群负载均衡时,Dubbo 提供了多种均衡策略,缺省为 ramdom 随机调用

负载均衡策略:
RandomLoadBalance: 基于权重的随机负载机制
graph LR id1[orderService] id2[userService 1] id3[userService 2] id4[userService 3] id1 == 2/7 ==> id2 --- Weight=100 id1 == 4/7 ==> id3 --- Weight=200 id1 == 1/7 ==> id4 --- Weight=300- 随机,按权重设置随机概率。
- 在一个截面上碰撞的概率高,但调用量越大分布越均匀,而且按概率使用权重后也比较均匀,有利于动态调整提供者权重
RoundRobinLoadBalance: 基于权重的轮循的负载均衡机制
graph LR id0[1-2-3-1-2-2-2] id1[orderService] id2[userService 1] id3[userService 2] id4[userService 3] id1 === id0 id0 == 2/7 ==> id2 --- Weight=100 id0 == 4/7 ==> id3 --- Weight=200 id0 == 1/7 ==> id4 --- Weight=300- 轮循,按公约数后的权重设置轮循比率。
- 存在慢的提供者累计请求的问题,比如:第二台机器响应很慢,但没有宕机,当请求调到第二台时就会卡在那里,久而久之,所有的请求都卡在第二台上。
LeastActiveLoadBalance: 最少活跃—负载均衡机制
graph LR id1[orderService] id2[userService 1] id3[userService 2] id4[userService 3] id1 == 1 ==> id2 --- 100ms id1 == 0 ==> id3 --- 1000ms id1 == 0 ==> id4 --- 300ms- 最少活跃调用数,相同活跃数的随机,活跃数指的是调用前后计数差。
- 能够使满的提供者收到更少的请求,因为越慢的提供者的调用前后计数差会越大
ConsistentHashLoadBalance: 一致性 Hash —负载均衡机制
graph LR id1[orderService] id2[userService 1] id3[userService 2] id4[userService 3] id1 == getUser?id=1 ==> id2 id1 == getUser?id=2 ==> id3 id1 == getUser?id=3 ==> id4- 一致性Hash,相同的参数的请求总是发送到同一提供者。
- 当某一台提供者宕机时,原本发往该提供者的请求,基于虚拟节点,平摊到其他提供者,不会引起剧烈变动。算法参见:http://en.wikipedia.org/wiki/Consistent_hashing
- 缺省只对第一个参数 Hash,如果要修改,请配置
<dubbo:parameter key="hash.arguments" value="0,1" /> - 缺省用 160 分虚拟节点,如果需要更改,请配置
<dubbo:parameter key="hash.nodes" value="320" />
如何配置(以 XML 配置文件为例):
服务端服务级别
<dubbo:service interface="..." loadbalance="roundrobin" />@DubboService(loadbalance ="roundrobin")客户端服务级别
<dubbo:reference interface="..." loadbalance="roundrobin" />@DubboReference(loadbalance ="roundrobin")服务端方法级别
<dubbo:service interface="..."> <dubbo:method name="..." loadbalance="roundrobin"/> </dubbo:service>@DubboService(methods = {@Method(name = "...", loadbalance ="roundrobin")})客户端方法级别
<dubbo:reference interface="..."> <dubbo:method name="..." loadbalance="roundrobin"/> </dubbo:reference>@DubboReference(methods = {@Method(name = "...", loadbalance ="roundrobin")})
如何设置权重:
Dubbo 可以在 @DubboService 中使用 weight 参数来设置服务权重,不过为了达到动态调整的效果,通常情况下是在 Dubbo Admin 管理界面中进行倍权/半权等调整

旧版 Dubbo Admin 可以直接在愿意偶的基础上修改权限,但是新版的 Dubbo Admin 只能在权限调整页面上新建原服务名对应的权重配置来进行覆盖

3. 服务降级
什么是服务降级:
当服务压力剧增的情况下,根据实际业务情况及流量,对一些服务和页面有策略地不处理或者是换种简单的方式处理,从而释放服务器资源以保证核心交易正常运作或高效运作。
可以通过服务降级功能临时屏蔽某个出错的非关键服务,并定义降级后的返回策略。
向注册中心写入动态配置覆盖规则:
RegistryFactory registryFactory = ExtensionLoader.getExtensionLoader(RegistryFactory.class).getAdaptiveExtension();
Registry registry = registryFactory.getRegistry(URL.valueOf("zookeeper://10.20.153.10:2181"));
registry.register(URL.valueOf("override://0.0.0.0/com.foo.BarService?category=configurators&dynamic=false&application=foo&mock=force:return+null"));
其中:
mock=force:return+null:屏蔽,表示消费方对该服务的方法调用都直接返回null值,不发起远程调用。用来屏蔽不重要服务不可用时对调用方的影响。mock=fail:return+null:容错,表示消费方对该服务的方法调用在失败后,再返回null值,不抛异常。用来容忍不重要服务不稳定时对调用方的影响。
服务降级可以直接在 Dubbo Admin 中进行设置(目前新版的 Dubbo Admin 相关功能还在开发中,将会在后续版本中发布)
4. 集群容错
在集群调用失败时,Dubbo 提供了多种容错方案,缺省为 failover 重试。
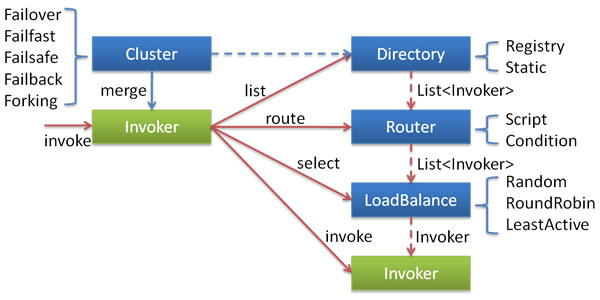
各节点关系:
- 这里的
Invoker是Provider的一个可调用Service的抽象,Invoker封装了Provider地址及Service接口信息 Directory代表多个Invoker,可以把它看成List<Invoker>,但与List不同的是,它的值可能是动态变化的,比如注册中心推送变更Cluster将Directory中的多个Invoker伪装成一个Invoker,对上层透明,伪装过程包含了容错逻辑,调用失败后,重试另一个Router负责从多个Invoker中按路由规则选出子集,比如读写分离,应用隔离等LoadBalance负责从多个Invoker中选出具体的一个用于本次调用,选的过程包含了负载均衡算法,调用失败后,需要重选
集群容错模式:
Failover Cluster(缺省)
失败自动切换,当出现失败,重试其它服务器。通常用于读操作,但重试会带来更长延迟。可通过
retries="2"来设置重试次数(不含第一次)。重试次数配置如下:
<dubbo:service retries="2" /><dubbo:reference retries="2" /><dubbo:reference> <dubbo:method name="..." retries="2" /> </dubbo:reference>@DubboService(retries = "2")@DubboReference(retries = "2")@DubboReference(methods = {@Method(name = "...", retries = "2")})
Failfast Cluster
- 快速失败,只发起一次调用,失败立即报错。通常用于非幂等性的写操作,比如新增记录。
Failsafe Cluster
- 失败安全,出现异常时,直接忽略。通常用于写入审计日志等操作。
Failback Cluster
- 失败自动恢复,后台记录失败请求,定时重发。通常用于消息通知操作。
Forking Cluster
- 并行调用多个服务器,只要一个成功即返回。通常用于实时性要求较高的读操作,但需要浪费更多服务资源。可通过
forks="2"来设置最大并行数。
- 并行调用多个服务器,只要一个成功即返回。通常用于实时性要求较高的读操作,但需要浪费更多服务资源。可通过
Broadcast Cluster
广播调用所有提供者,逐个调用,任意一台报错则报错。通常用于通知所有提供者更新缓存或日志等本地资源信息。
现在广播调用中,可以通过
broadcast.fail.percent配置节点调用失败的比例,当达到这个比例后,BroadcastClusterInvoker将不再调用其他节点,直接抛出异常。broadcast.fail.percent取值在0~100范围内。默认情况下当全部调用失败后,才会抛出异常。broadcast.fail.percent只是控制的当失败后是否继续调用其他节点,并不改变结果(任意一台报错则报错)。broadcast.fail.percent参数 在 Dubbo 2.7.10 及以上版本生效。Broadcast Cluster 配置
broadcast.fail.percent。broadcast.fail.percent=20代表了当 20% 的节点调用失败就抛出异常,不再调用其他节点。示例:
@reference(cluster = "broadcast", parameters = {"broadcast.fail.percent", "20"})
集群模式配置:
按照以下示例在服务提供方和消费方配置集群模式
<dubbo:service cluster="failsafe" />
<dubbo:reference cluster="failsafe" />
@DubboService(cluster = "failsafe")
@DubboReference(cluster = "failsafe")
5. Dubbo 整合 Hystrix
Hystrix 旨在通过控制那些访问远程系统、服务和第三方库的节点,从而对延迟和故障提供更强大的容错能力。Hystrix 具备拥有回退机制和断路器功能的线程和信号隔离,请求缓存和请求打包,以及监控和配置等功能
5.1. 配置 spring-cloud-starter-netflix-hystrix(提供者和消费者都要)
SpringBoot 官方提供了对 Hystrix 的集成,可以直接在 pom.xml 中引入 spring-cloud-starter-netflix-hystrix(注意⚠️:一定要先引入 spring-cloud-starter,否则运行的时候会出现错误)
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter</artifactId>
<version>3.1.0</version>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
<version>2.2.10.RELEASE</version>
</dependency>
让后在 Application 类上增加 @EnableHystrix 来启动 hystrix-starter
@SpringBootApplication
@EnableDubbo
@EnableHystrix
public class Application {
public static void main(String[] args) {
SpringApplication.run(BootUserServiceProviderApplication.class, args);
}
}
5.2. 配置服务提供者端
在需要 Hystrix 代理的方法上添加 @HystrixCommand 来实现代理
@Override
@HystrixCommand
public List<UserAddress> getUserAddressList(String userId) {
UserAddress address1 = new UserAddress(1, "Address1", "1", "XiaoMing", "1234567890", "Y");
UserAddress address2 = new UserAddress(2, "Address2", "2", "XiaoHong", "9876543210", "Y");
System.out.println("This is server 2");
if ( Math.random() > 0.5 ) {
throw new RuntimeException();
}
return Arrays.asList(address1, address2);
}
5.3. 配置服务消费者端
在需要调用远程方法的方法上添加 @HystrixCommand(fallBackMethod = "...") 来设置调用失败后的回调方法
@Override
@HystrixCommand(fallbackMethod = "hello")
public List<UserAddress> initOrder(String userId) {
System.out.println("User id: " + userId);
// 1. Query the receiving address of the user
List<UserAddress> addressList = userService.getUserAddressList(userId);
for (UserAddress userAddress : addressList) {
System.out.println(userAddress.getUserAddress());
}
return addressList;
}
public List<UserAddress> hello(String userId) {
return List.of(new UserAddress(10, "Test address", "1", "Test", "Test", "Y"));
}

